某电商系统的核心订单表如下
1 2 3 4 5 6 7 8 9 CREATE TABLE orders ( order_id BIGINT PRIMARY KEY , user_id INT , product_id INT , status VARCHAR (20 ), create_time DATETIME, amount DECIMAL (10 , 2 ), INDEX idx_user(user_id) );
商品表面临以下问题,请分析原因并给出解决方案
订单表的分页查询 SELECT * FROM orders WHERE status='completed' ORDER BY create_time DESC LIMIT 100000, 20; 耗时 12 秒,请优化 SQL 并设计业务分页方案
测试 先自己建一张表然后往里面插 5000000 条数据测试一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 DROP PROCEDURE IF EXISTS insert_orders;DELIMITER $$ CREATE PROCEDURE insert_orders()BEGIN DECLARE i INT DEFAULT 1 ; WHILE i <= 5000000 DO INSERT INTO test.orders (order_id, user_id, product_id, status, create_time, amount) SELECT i + seq.seq AS order_id, FLOOR (RAND() * 1000 ) + 1 AS user_id, FLOOR (RAND() * 500 ) + 1 AS product_id, 'completed' AS status, NOW() - INTERVAL FLOOR (RAND() * 365 ) DAY AS create_time, ROUND(RAND() * 1000 , 2 ) AS amount FROM ( SELECT 0 AS seq UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 UNION ALL SELECT 12 UNION ALL SELECT 13 UNION ALL SELECT 14 UNION ALL SELECT 15 UNION ALL SELECT 16 UNION ALL SELECT 17 UNION ALL SELECT 18 UNION ALL SELECT 19 UNION ALL SELECT 20 UNION ALL SELECT 21 UNION ALL SELECT 22 UNION ALL SELECT 23 UNION ALL SELECT 24 UNION ALL SELECT 25 UNION ALL SELECT 26 UNION ALL SELECT 27 UNION ALL SELECT 28 UNION ALL SELECT 29 UNION ALL SELECT 30 UNION ALL SELECT 31 UNION ALL SELECT 32 UNION ALL SELECT 33 UNION ALL SELECT 34 UNION ALL SELECT 35 UNION ALL SELECT 36 UNION ALL SELECT 37 UNION ALL SELECT 38 UNION ALL SELECT 39 UNION ALL SELECT 40 UNION ALL SELECT 41 UNION ALL SELECT 42 UNION ALL SELECT 43 UNION ALL SELECT 44 UNION ALL SELECT 45 UNION ALL SELECT 46 UNION ALL SELECT 47 UNION ALL SELECT 48 UNION ALL SELECT 49 UNION ALL SELECT 50 UNION ALL SELECT 51 UNION ALL SELECT 52 UNION ALL SELECT 53 UNION ALL SELECT 54 UNION ALL SELECT 55 UNION ALL SELECT 56 UNION ALL SELECT 57 UNION ALL SELECT 58 UNION ALL SELECT 59 UNION ALL SELECT 60 UNION ALL SELECT 61 UNION ALL SELECT 62 UNION ALL SELECT 63 UNION ALL SELECT 64 UNION ALL SELECT 65 UNION ALL SELECT 66 UNION ALL SELECT 67 UNION ALL SELECT 68 UNION ALL SELECT 69 UNION ALL SELECT 70 UNION ALL SELECT 71 UNION ALL SELECT 72 UNION ALL SELECT 73 UNION ALL SELECT 74 UNION ALL SELECT 75 UNION ALL SELECT 76 UNION ALL SELECT 77 UNION ALL SELECT 78 UNION ALL SELECT 79 UNION ALL SELECT 80 UNION ALL SELECT 81 UNION ALL SELECT 82 UNION ALL SELECT 83 UNION ALL SELECT 84 UNION ALL SELECT 85 UNION ALL SELECT 86 UNION ALL SELECT 87 UNION ALL SELECT 88 UNION ALL SELECT 89 UNION ALL SELECT 90 UNION ALL SELECT 91 UNION ALL SELECT 92 UNION ALL SELECT 93 UNION ALL SELECT 94 UNION ALL SELECT 95 UNION ALL SELECT 96 UNION ALL SELECT 97 UNION ALL SELECT 98 UNION ALL SELECT 99 ) AS seq; SET i = i + 100 ; END WHILE; END $$DELIMITER ; CALL insert_orders();
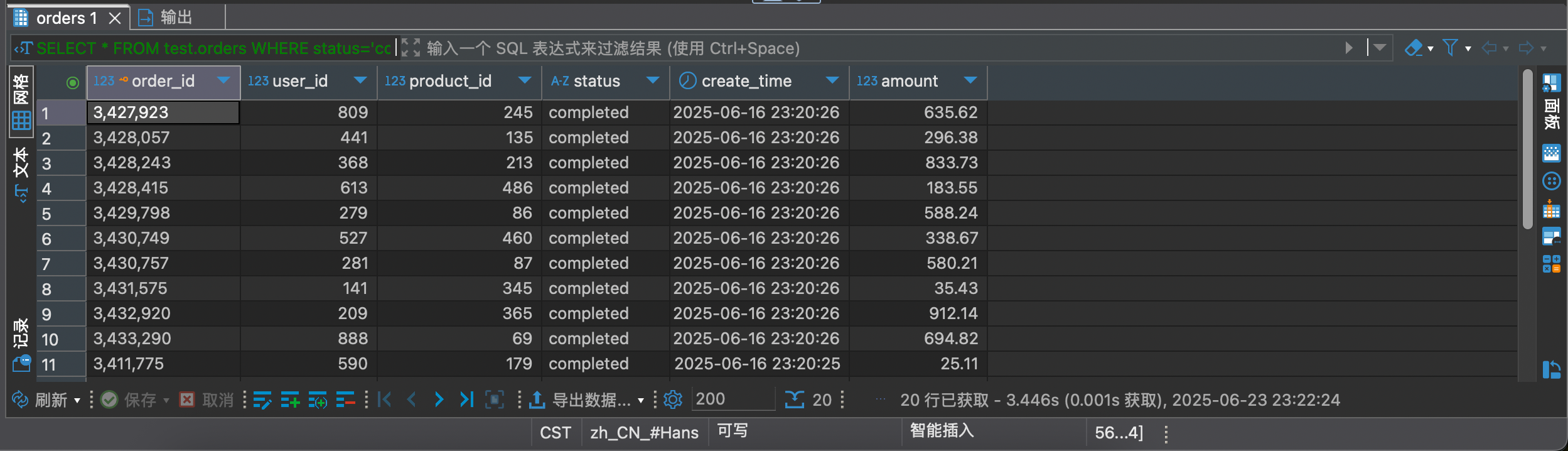
测试一波,结果当然是很惨的,直接跑了 3.446s
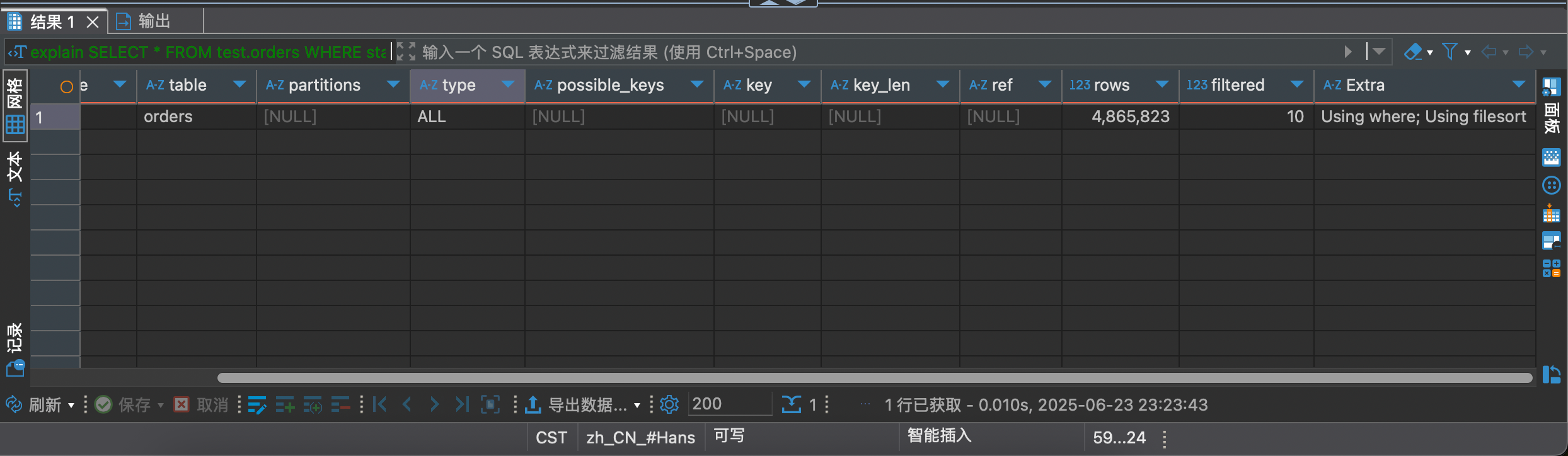
用 explain 分析一下
结果也是不负众望的走了全表扫描
建索引 大部分人优化这个 SQL 的第一反应应该是给 status 和 create_time 建立联合索引
1 CREATE INDEX idx_status_time ON test.orders (status, create_time);
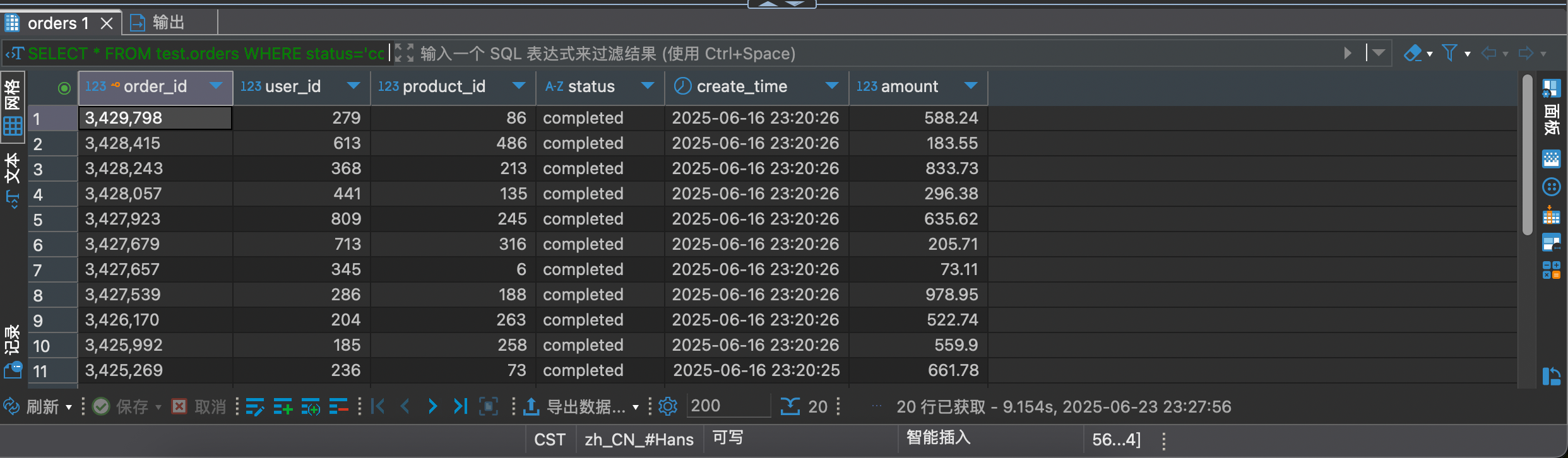
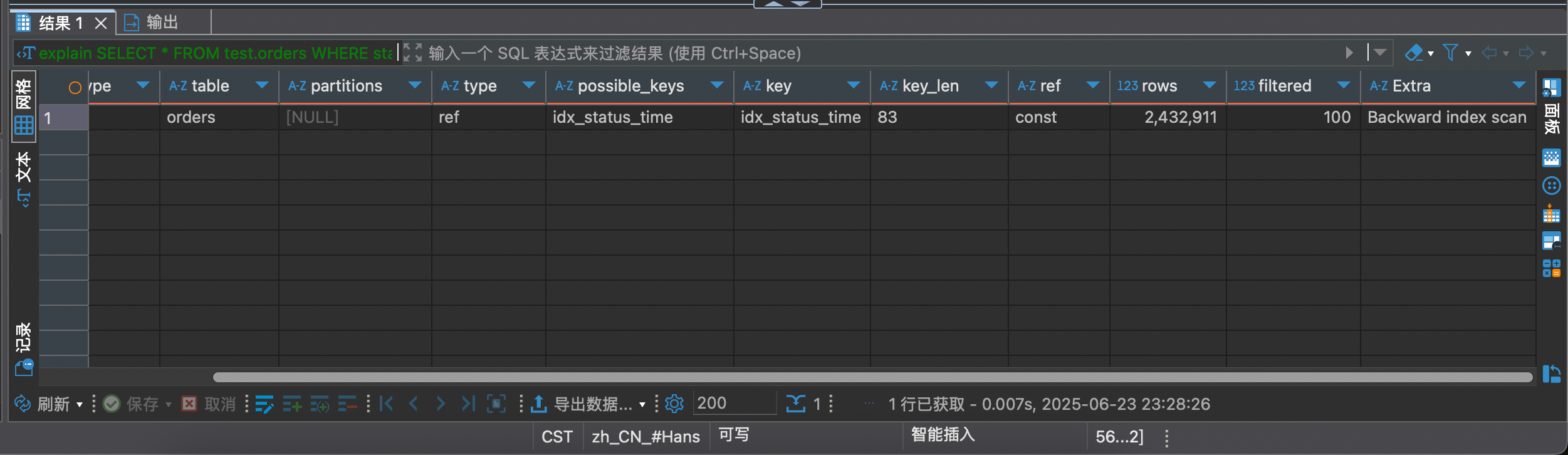
再看一下执行速度和语句分析
虽然用了联合索引,但是由于回表查询,导致查询结果更慢了
那么有没有办法既用联合索引,还能降低回表查询带来的负影响呢?有的兄弟有的,那就是延迟关联
延迟关联 延迟关联是一种优化 大分页 + 多字段查询 的经典技术,通过先只查索引上的主键做分页,之后再根据主键回表获取完整数据
直接贴 SQL 就一目了然了
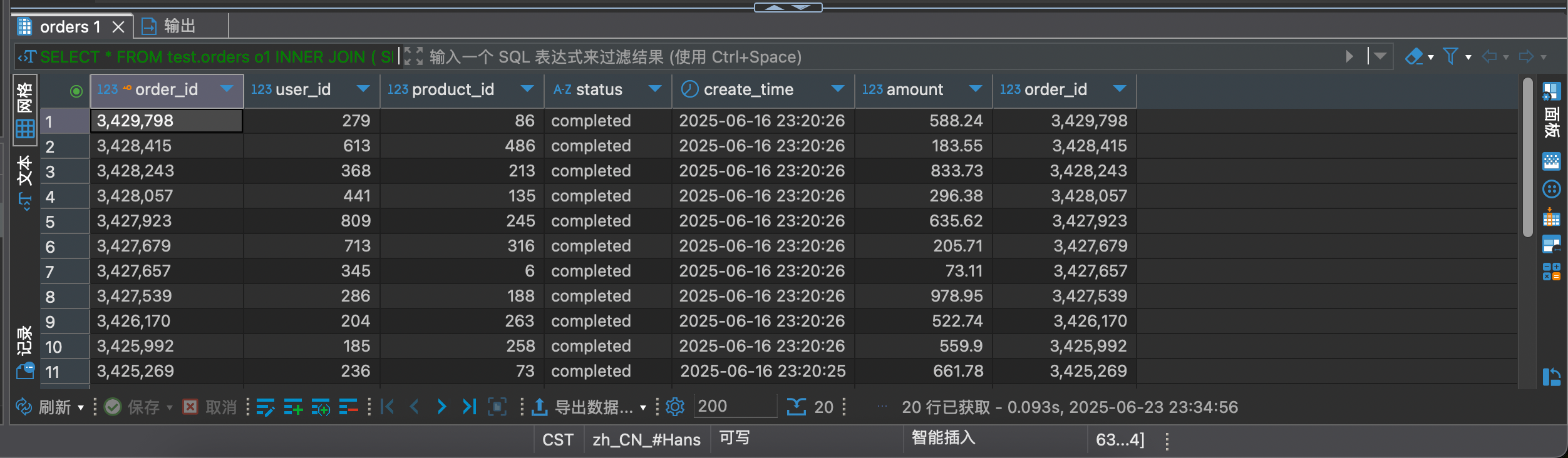
1 2 3 4 5 6 7 8 9 SELECT * FROM test.orders o1INNER JOIN (SELECT order_id FROM test.orders WHERE status = 'completed' ORDER BY create_time DESC LIMIT 100000 , 20 ) as o2 ON o1.order_id = o2.order_id;
这样就可以先利用联合索引找出结果中的 order_id,再延迟回表进行查询
虽然这样也进行了回表查询,但是至多只需要回表 20 次,不需要回表 100020 次
只需要 0.093s,遥遥领先于同行
延迟关联这种思想,既然可以通过连接表实现,当然也能通过子查询实现
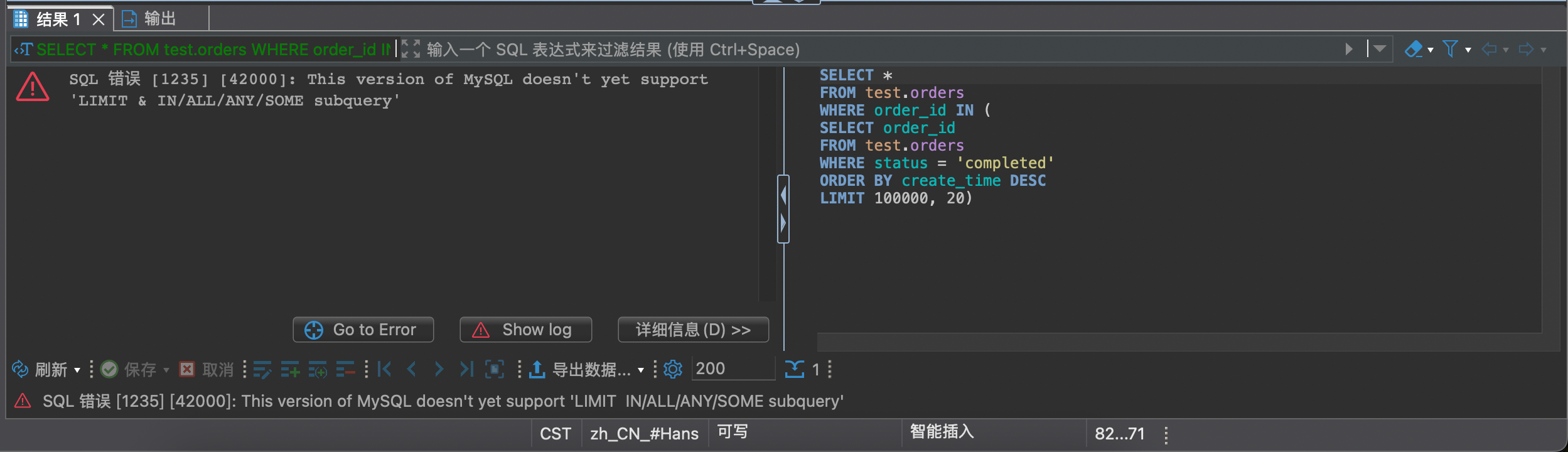
1 2 3 4 5 6 7 8 SELECT * FROM test.ordersWHERE order_id IN (SELECT order_id FROM test.orders WHERE status = 'completed' ORDER BY create_time DESC LIMIT 100000 , 20 );
哄堂大笑了,8.4.5 版本的 MySQL 根本不支持在子查询中用 limit
理论分析一下,子查询这个东西,外层查询的每一行都要执行一次子查询,相当于嵌套循环,当外层数据量很大时,性能会急剧下降,能连接表还是连接表吧